In modern API design it is pretty common to send and return JSON formatted data, it is the de-facto standard but it doesn’t mean that we should always use JSON, sometimes other formats are easier to handle and more efficient for specific use cases, let me explain.
The RE in REST stands for REpresentational, this API style, as the name says is all about State Transfer using a specific REpresentation, but what does this actually mean?
Say we have an API modeling books, we would normally represent the book with JSON like this:
{
"id": "1234",
"title": "I Robot",
"author": "Isaac Asimov",
"description": "This book is too good. If you are into AI you must read it!"
}
We could also represent the book using XML:
<book>
<id>1234</id>
<title>I Robot</title>
<author>Isaac Asimov</author>
<description>This book is too good. If you are into AI you must read it!</description>
</book>
The books contain the same data, we only changed the way they are represented.
Now, let me tell you about a project I worked on that was having severe performance issues as it was handling enormous amounts of data and a specific endpoint, under certain conditions, would return 120MB worth of data!
The application was showing tabular data and line charts and it allowed users to filter contents and specify a date range. The API I am talking about returned a timeseries and had no pagination due to business requirements apparently, the frontend was extremely laggy and my goal was to optimize this behemoth and make it work smoothly even when that huge blob of data was being requested.
The first problem I noticed with the data being returned was the way it was represented, it was essentially a list of thousands of data points looking something like this:
{
"data": [
{ "id": 1, "group": "1234", "value": 9999.9, "timestamp": "2020-01-01T01:01:00Z", "unit": "xyz" },
{ "id": 2, "group": "1234", "value": 9900.0, "timestamp": "2020-01-01T01:02:00Z", "unit": "xyz" },
{ "id": 3, "group": "1234", "value": 9980.0, "timestamp": "2020-01-01T01:03:00Z", "unit": "xyz" },
{ "id": 4, "group": "1234", "value": 9960.5, "timestamp": "2020-01-01T01:04:00Z", "unit": "xyz" },
]
}
The first thing I noticed was just how wasteful JSON was for this use case as each record had the same exact fields repeated over and over, so my first idea came from Data Oriented Design (DOD) commonly applied in videogame engines and databases. As you might already know some databases store data row-wise (usually in SQL databases such as MySQL, SQLite and PostgreSQL) while others such as AWS Redshift or Google BigQuery store data column-wise.
My next thought was, why not apply some DOD techniques to the data returned by this endpoint? To remove all the repeated fields I initially flipped the data representation from a list of objects to an object of lists where each key-value pair would represent a table column:
{
"data": {
"id": [1,2,3,4],
"group": ["1234","1234","1234","1234"],
"value": [9999.9,9900.0,9980.0,9960.5],
"timestamp": ["2020-01-01T01:01:00Z","2020-01-01T01:02:00Z","2020-01-01T01:03:00Z","2020-01-01T01:04:00Z"],
"unit": ["xyz","xyz","xyz","xyz"]
}
}
A sample of 100 records from the API with the row-based representation occupied around 12KB while the column based representation took around 5KB of disk space, a 60% size reduction only by switching the data representation! This was already a massive improvement, but we can do better!
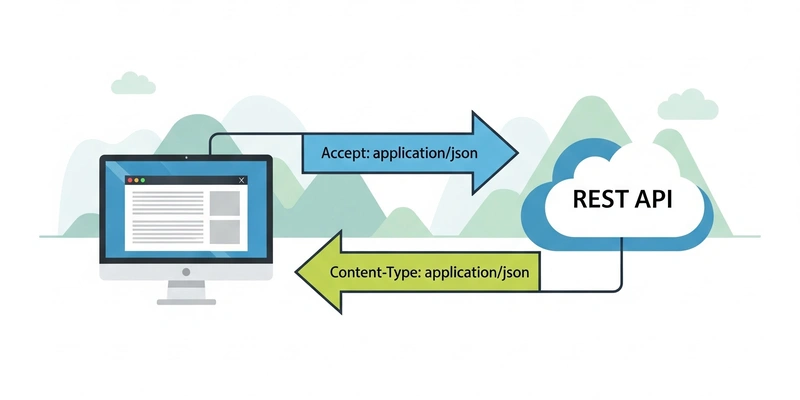
The endpoint was essentially returning tabular data with close to no manipulation done on the backend, so I thought, why not simplify it even further and directly format the data as CSV? This is where content negotiation and the RE in REST come into play.
One of the core ideas of REST APIs is that you can represent content using different formats and the way you do it is by
leveraging the Accept and Content-Type HTTP headers.
The mechanism is quite simple to implement:
- the client performs an API call and includes the HTTP header with the format it desires, in this case
Accept: text/csv - the API endpoint checks the
Acceptheader from the request and verifies if it supports the MIME type - if it does not it responds with the status code
406 Not Acceptable - if it does, it responds with a
Content-Type: text/csvheader and the body serialized accordingly
Adding CSV serialization on the API endpoint was quite straightforward and adding the content negotiation was as simple as writing the following code (example using Node.js and express.js v5):
function handler(request, response) {
const data = getDataFromDatabase(request)
response.format({
'text/csv'() {
const csv = formatAsCSV(data)
response.send(csv)
},
'application/json'() {
res.send({ data })
}
})
}
// alternatively you can use the request.accepts('text/csv') method
As a final API optimization I then enabled server side compression using gzip, I then ran multiple tests with the different variations (row/col based, JSON/CSV, with/without gzip) and found out that the most optimal one for this dataset was the row-based CSV representation with gzip.
Switching to CSV had some disadvantages as I needed to add some custom logic on the frontend to parse the data. This was probably not the best solution to the API’s lack of pagination but it was a pretty effective one considering its simplicity. Telling the customer that I managed to get a 90% reduction in network traffic (120MB down to ~12MB) this quickly was an easy sell considering we had a quite limited budget!
So what did we learn from all this?
- It is ok to Accept other Content Types beyond JSON and use content negotiation!
- Some DOD techniques and that sometimes an “object of lists” can be better than a “list of objects”
- Returning CSV from a REST API is ok for some use cases
- Network time is more expensive than CPU time, use server side compression!
- I did not mention it in the post but, use virtual scrolling for very large tables in your frontends!
Have fun with your REST APIs and stay tuned for more! :)
If you liked this post or your API is having performance issues, let me know as I am always open to connecting!